Why No Test Cases
The test team I lead do not use test cases. We believe that testing is an active, changing exercise and that rigid test cases does not support this rate of change. I will give my arguments for not using test cases before explaining how we do plan and track our testing
What is a test case?
A test case defines a process that will show if the software you are testing displays a particular desirable attribute. It consists of 3 main parts:
- Starting condition
- Method
- End condition
And may have other parameters
- Priority
- Owner
- Status (open, in progress, blocked, closed)
- Weight
A low level test plan is a collection of these test cases for a particular module or capability of the software being tested. The test plan is reviewed and approved by stakeholders rather than an individual review of each test case.
Reasons for change
Not all test cases are created equal
To paraphrase George Orwell "all test cases are created equally, but some test cases are more equal than others". Each test case differs from others in terms of it’s:
- Risk
- Complexity
- Duration
Tests when executed reduce the risk of faulty software being shipped to the customer. From the customers perspective there are different levels of risk, some acceptable and some not. The risk of a small input validation error within a utility program might be just annoying but other errors could cause a loss of money within a business or even loss of life for aviation or medical software. Different tests mitigate different amounts of risk.
The complexity of a test case can also vary. Modern software is rarely executed on it’s own and will likely have many integration points. Configuring, executing and monitoring the software during the test can be a complex task. Some simpler test cases though are a lot less complex.
Tests not only take time to execute but also can take considerable time to prepare the required test configurations and test harness to execute the test. As well as time required by the tester to complete these tasks, longevity or workload tests can then take an extended period of elapsed time to execute the test. Validation of the test execution data once the test has executed will also add to the duration of the test case.
Some tests will have a natural ordering between them. Quite often a test will build on top of previously run tests. These tests will require the tests run earlier to pass in order for this test to be run.
The above points show how varied and different a set of tests can be. Defining these varied and many tests into a single unified ‘test case’ hides the differences between them. Once in this form they are counted as if they were all identical in duration, risk and complexity. Boiling this complexity into a single test case template just hurts the testing.
Preparatory work
Any test case will require some degree of preparatory work before the 'actual test' can get underway. This might be configuring automation, defining workloads or developing test harness to run the test. Is this work part of the testing process or just necessary delay that has to be done before the real work starts. Fellow testers seem to fall into one of two main schools of thought. One group see prep work as a required evil, work that must be done but isn't part of the actual testing. The other group are of the thinking that as soon as you start to interact with the new parts of the software, the process of testing has begun. Either way how do you classify this work? It doesn't fit into the test case template at all and yet the test cases are dependant on it being done. When a team has 10 test cases remaining you don't know what work needs to be done to execute those tests? They might need 3 days of prep work to be done first.
Once the prep work is completed you are left with a set of test cases and a period of time to complete them in. This turns the test case into a metric and ...
Someone always wants to track them
There are x number of test cases left to do and y amount of time left to do it. Simplistically this is modelled by a straight line graph. The model assumes that each test can be executed in the same amount of time.
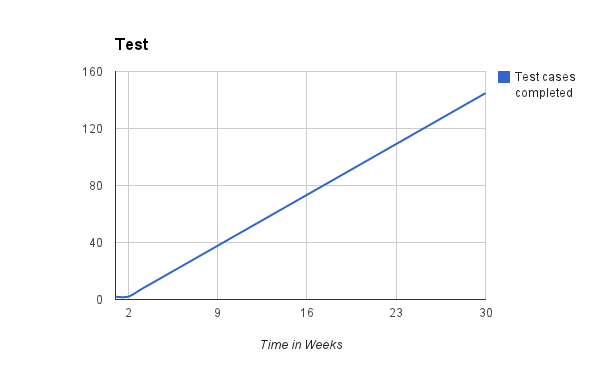
However as we have said before not all test cases are equal, so to assume that we can execute through them in a linear fashion is short sighted. Also as test work progresses defects are raised which will require recreation and verification and this takes time, time that cannot then be spent on executing tests. Responding to this the chart is often re-drawn as an s-curve like this one:
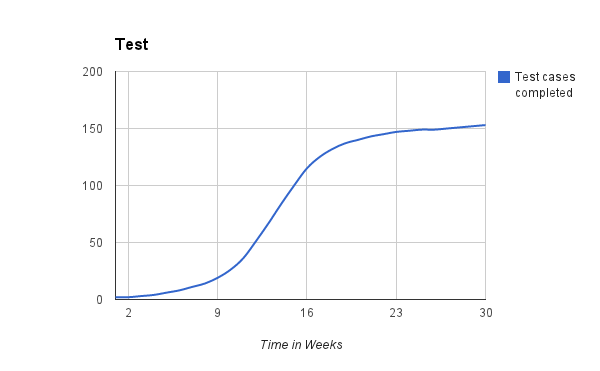
Progress is charted against the graph and teams either are congratulated or receive 'management focus' depending on the state of the chart. This misses the point and it's largely the fault of the test cases. Progress through a list of predefined tests means nothing. For the progress to be meaningful you need to assume that the quality of the tests are high and that the tests mitigate the majority of the risk for the customer. Even if you can make that assumption, progress through the test cases isn't enough to judge progress you also need to consider:
- How many defects testers are finding.
- The spread of defects across the product
- What tests have actually been done yet (have we just done the easy ones)
- what if we have completed 90% of the test cases and found no defects?
Without this additional information the complexity of testing is abandoned in favour of an overly simplified metric which is too narrow to be of any real use.
They don't react well to change
Testing is an exploratory sport, an experienced tester working through any set of test cases will question their approach based upon; progress through the test case, prior defects and often just a gut feeling. Regardless of how much thought and effort is applied to the formulation of the test plan, the planned testing and the actual testing will be different. This is because the tester is learning about the software and how it was implemented as they execute the tests. A single test case might expose a bug which is part of a bug cluster within a piece of code. To fully examine the area new test cases will be created and executed on the fly. This ad-hoc, off piste or exploratory testing should result in further test cases being written and added to the plan. Adding extra tests often infuriates managers trying to track progress. The new tests are driving further quality into the product and their value isn't in the testcase being written but in it being executed and the defects that they find.
Test approaches such as scenario based, use-case or exploratory do not lend themselves to a formal test case report. They often do not have a particular method or starting condition but instead tend to rely on experienced confident testers examining the product in the same way the intended customer would. These approaches are better tracked using a time box or complexity rating like duration or story points.
Test cases seem like a good idea. However in reality they are too simple a model to use in practice. A single test case can define the intent of a test but the model breaks when used to suggest progress or the quality of the product.
I explained this to a junior member of my team and drew parallels between some exploratory testing he wanted to achieve and a prototyping story that development were planning. Both didn't have a clear plan of implementation but they did have allotted time and a focus on learning how to achieve their aim by 'working with the software'.
This was when an alternative became clear. This is just software engineering. Can't we measure software development and texecute.work in the same way? Would that makes things clearer
Whats the alternative
Test work is just engineering work
If you stop thinking about testing as being the execution of test cases and instead as another type of software engineering work then an alternative approach becomes obvious. Testers still write code, examine specifications and solve problems in the same way as a developer. We don't track developers by the number of changesets they produce so why not treat testers in the same way and use the same tracking artefacts that are used in development.
We now use test stories for our system. Test work. No test cases in sight.
A Test Story is similar to a development story. It outlines the objective of the work, priority, owner and complexity. Except in a test story the objective could be more deconstructive than that of development story. As a dev story is constructing something new, test are de-constructing it to reveal defects.
Test Stories can be planned for an iteration and split into multiple child tasks that describe each individual unit of work. The test story is given an estimate of the time it might take, a priority of how important it is that this test is executed and a story point rating to describe how complex this test is to implement and execute
Handling defects
Defects found during the story executuon are linked to the work item to show the 'fruit' of that story. Development and test stories can be associated to show the testing that will be applied to new capability
Defects that are found will often require recreating to provide further diagnostics and require verification once a fix is supplied. This work will need to be planned and committed to an iteration just like any other piece of work. We have created queries to total the amount of time spent 'working' these defects. This can help to explain delays in test progress as testers are working on defects.
Showing progress
We can now show our progress by explaining the work we have committed in an iteration and our burn down throughout the iteration. Not using the simple metric of testcases focuses people to ask more interesting questions to determine the quality of the project:
- What types of testing have we done?
- What defects have we found?
- How much time do we need to complete the high priority work
All more valid and useful than a single percentage of test case completion.
We have been using test stories as a replacement for test cases in the system test team for a few releases. Using them has given us the following benefits:
- The total amount of test work that needs to be done including prep, defect recreation and verification as well as actual testing. We can plan our iterations a lot better.
- Tracking is a lot easier as we can understand the duration as well as the complexity of the work rather than simple counting measures
- We are starting to ask better questions about the state of the test project.
We still are not perfect. We are still refining our process to ensure we estimate tasks better and ensure we don't fall into the trap of just counting test stories. Overall we have seen an improvement in out efficiency. Who needs test cases? Not us!

